学到什么
- 并发与并行的区别?
- 什么是 Goroutine?
- 什么是通道?
- Goroutine 如何通信?
- 相关函数的使用?
select语句如何使用?
并发与并行
为了更有意思的解释这个概念,我借用知乎上的一个回答:
- 你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
- 你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
- 你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
并发的关键是你有处理多个任务的能力,不一定要同时。
并行的关键是你有同时处理多个任务的能力。
对应到 CPU 上,如果是多核它就有同时执行的能力,即有并行的能力。
对于 Go 语言,它自行安排了我们的代码合适并发合适并行。
什么是 Goroutine
学会这个就知道怎么写一个并发程序,用起来很简单的,现在开始。
Goroutine 是 Go 语言中的协程,其它语言称为的协程字面上叫 Coroutine,简单理解下就是比线程更轻量的一个玩意。
再说白了,就是可以异步执行函数。
main Goroutine
当启动 main 入口函数时,后台就自动跑了一个 main Goroutine,还原给大家看看。
package main
func main() {
panic("看这里")
}
执行上面代码,会输出如下部分信息:
panic: 看这里
goroutine 1 [running]:
main.main()
从结果中可以看到,出现了一个 goroutine 字眼,它对应的索引为 1。
创建 Goroutine
创建 Goroutine 很简单,只需要在函数前增加一个 go 关键字,格式如下:
go fun1(...)
也支持匿名函数。
go func(...){
// ...
}(...)
go关键字后的函数可以写返回值,但无效。因为 Goroutine 是异步的,所以没法接受。
下来看一个完整的例子:
package main
import (
"fmt"
)
func PrintA() {
fmt.Println("A")
}
func main() {
go PrintA()
fmt.Println("main")
}
看上面 main 函数只有两行:
- 第一行:创建一个 Goroutine,异步打印“A”字符串。
- 第二行:打印 “main” 字符串。
现在先停留一会,想想执行该代码后,输出结果是啥。
结果如下:
main
你没看错,没有输出“A”字符串。
因为 go PrintA() 创建的 Goroutine 它是异步执行,main 函数执行完退出程序时,也不会管它。所以下来看如何让 main 函数等待 Goroutine 执行完。
方法一:使用 time.Sleep 函数。
func main() {
go PrintA()
fmt.Println("main")
time.Sleep(time.Second)
}
// 输出
main
A
main 函数退出前让等一会。
方法二:使用空的 select 语句,非空的 select 用法会配合通道一块讲解。
func main() {
go PrintA()
fmt.Println("main")
select {}
}
// 输出
main
A
fatal error: all goroutines are asleep - deadlock!
...
"A" 字符串是输出了,但程序也出现异常了。
原因是,当程序中存在运行的 Goroutine,select{} 就会一直等待,如果 Goroutine 都执行结束了,没有什么可等待的了,就会抛出异常。
在真实项目中,出现异常自然不对,那 select{} 使用场景是啥,例如:
- 爬虫项目,创建了 Goroutine,需要一直爬取数据,不需要停止。
方法三:使用 WaitGroup 类型等待 Goroutine 结束,项目中常常使用,完整例子如下:
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func PrintA() {
fmt.Println("A")
wg.Done()
}
func main() {
wg.Add(1)
go PrintA()
wg.Wait()
fmt.Println("main")
}
- 声明
WaitGroup类型变量wg,使用时无需初始化。 wg.Add(1)表示需要等待一个 Goroutine,如果有两个,使用Add(2)。- 当一个 Goroutine 运行完后使用
wg.Done()通知。 wg.Wait()等待 Goroutine 执行完。
控制并发数
Go 语言中可以控制使用 CPU 的核心数量,从 Go1.5 版本开始,默认设置为 CPU 的总核心数。如果想自定义设置,使用如下函数:
num := 2
runtime.GOMAXPROCS(num)
num 如果大于 CPU 的核心数,也是允许的,Go 语言调度器会将很多的 Goroutine 分配到不同的处理器上。
什么是通道
现在明白了怎么创建 Goroutine 后,下一步就要知道它们之间要如何通信。
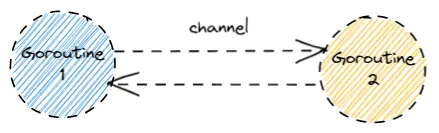
Goroutine 通信使用“通道 (channel)”,如果 Goroutine1 想发送数据给 Goroutine2,就把数据放到通道里,Goroutine2 直接从通道里拿就行,反过来也是一样。
在给通道放数据时,也可以指定通道放置的数据类型。
创建通道
创建通道时,分为无缓冲和有缓冲两种。
1. 无缓冲
strChan := make(chan string)
定义了一个存储数据类型为 string 的无缓冲通道,如果想存储任意类型,那数据类型设置为空接口。
allChan := make(chan interface{})
创建好了通道,下来就要给通道里放数据。
strChan := make(chan string)
strChan <- "老苗"
使用 "<-" 操作符链接数据,表示将“老苗”字符串送入 strChan 通道变量。
但这样放数据是会报错的,因为 strChan 变量是无缓冲通道,放入数据时 main 函数会一直等待,因此会造成死锁。
如果想解决死锁情况,就要保证有地方在异步读通道,因此需要创建一个 Goroutine 来负责。
例子如下:
// concurrency/channel/main.go
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func Read(strChan chan string) {
data := <-strChan
fmt.Println(data)
wg.Done()
}
func main() {
wg.Add(1)
strChan := make(chan string)
go Read(strChan)
strChan <- "老苗"
wg.Wait()
}
// 输出
老苗
Read函数负责读取通道数据,并打印。- 通道是引用类型,因此传递时无需使用指针。
<-strChan表示从通道里拿数据,如果通道里没有数据它会进行阻塞。wg.Wait()等待Read异步函数执行完。
2. 有缓冲
读了上面就会了解到,对于无缓冲通道,它会产生阻塞。为了不让阻塞,必须创建一个 Goroutine 负责从通道读取才行。
而有缓冲的通道,会有缓冲的余地,具体来看看。
创建缓冲通道,如下:
bufferChan := make(chan string, 3)
- 创建了一个存储数据类型为 string 的通道。
- 可以缓冲 3 个数据,即给通道送入 3 个数据不会进行阻塞。
测试如下:
// concurrency/bufferchannel/main.go
package main
import "fmt"
func main() {
bufferChan := make(chan string, 3)
bufferChan<-"a"
bufferChan<-"b"
bufferChan<-"c"
fmt.Println(<-bufferChan)
}
// 输出
a
- 给
bufferChan变量存入 3 个字符串。 - 存入 3 个数据时不会阻塞,当存入数量超过 3 时,就需要 Goroutine 异步读取。
缓冲通道何时使用,例如:
爬虫数据,第 1 个 Goroutine 负责爬取数据,第 2 个 Goroutine 负责处理和存储数据。 当第 1 个的处理速度大于第 2 个时,可以使用缓冲通道暂存起来。
暂存起来后,第 1 个 Goroutine 就可以继续爬取,而不像无缓冲通道,放入数据时会阻塞,直到通道数据被读出,才能进行。
为了加深印象,再来一张图:
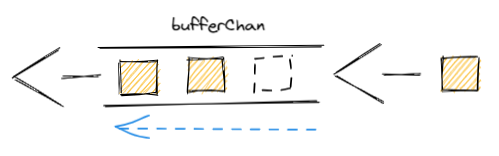
图解:
bufferChan长度为 3 的缓冲通道,并且已存入 2 个数据。- 看图中的两个箭头,箭头在
bufferChan右边,表示存,左边表示取。 - 按照先入先出规则存取。
单向通道
现在知道了如何创建一个双向通道,双向通道指的就是即可以存,又可以取。
那单向通道创建如下:
readChan := make(<-chan string)
writeChan := make(chan<- string)
readChan只能读取数据。writeChan只能存取数据。
但这样创建的通道是无法传递数据的,为什么?
因为,如果只能读的通道,没法存数据,那我存了个寂寞。而存的通道,我数据拿不出来,又有何用。
现在看看如何正确使用单向通道的例子,如下:
// concurrency/onechannel/main.go
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
// 写通道
func write(data chan<- int) {
data<-520
wg.Done()
}
// 读通道
func read(data <-chan int) {
fmt.Println(<-data)
wg.Done()
}
func main() {
wg.Add(2)
dataChan := make(chan int)
go write(dataChan)
go read(dataChan)
wg.Wait()
}
// 输出
520
- 创建了两个 Goroutine,
read函数负责只读,write函数负责只写。 - 通道传递时,将双向通道转化为单向通道。
遍历通道
在实际项目中,通道里会产生大量的数据,这时候就要循环的从通道里读取。
现在改写单向通道写入数据的例子:
func write(data chan<- int) {
for i := 0; i < 10; i++ {
data<-i
}
wg.Done()
}
这段代码是给通道里循环写入数字。
下来使用两种方式循环读取通道数据。
1. 死循环
func read(data <-chan int) {
for {
d := <-data
fmt.Println(d)
}
wg.Done()
}
使用死循环读取数据,但这个有个问题,什么时候退出 for 循环?
read 函数在读取通道时是不知道数据写入完了,如果读取不到数据,它会一直阻塞,因此,如果写数据完成时,需要使用 close 函数关闭通道。
func write(data chan<- int) {
// ...
close(data)
wg.Done()
}
关闭后,读取通道时也需要检测判断。
func read(data <-chan int) {
for {
d, ok := <-data
if !ok {
break
}
fmt.Println(d)
}
wg.Done()
}
ok变量为 false 时,表示通道已关闭。- 关闭通道后,
ok变量不会立马变成 false,而是等已放入通道的数据都读取完。
ch := make(chan string, 1)
ch <- "a"
close(ch)
val, ok := <-ch
fmt.Println(val, ok)
val1, ok1 := <-ch
fmt.Println(val1, ok1)
// 输出
a true
false
2. for-range
也可以使用 for-range 语句读取通道,这比死循环使用起来简单一点。
func read(data <-chan int) {
for d := range data{
fmt.Println(d)
}
wg.Done()
}
- 如果想退出 for-range 语句,也需要关闭通道。
- 如果关闭通道后,不需要增加 ok 判断,等通道数据读取完,自行会退出。
通道函数
使用 len 函数获取通道里还有多少个消息未读,cap 函数获取通道的缓冲大小
ch := make(chan int, 3)
ch<-1
fmt.Println(len(ch))
fmt.Println(cap(ch))
// 输出
1
3
select 语句
上面已经知道了空 select 语句的作用,现在看看非空 select 的用法。
select 语句 和 switch 语句类似,它也有 case 分支,也有 default 分支,但 select 语句的不同点有两个:
case分支只能是“读通道”或“写通道”,如果读写成功,即不阻塞,则case分支就满足。fallthrough关键字不能使用。
1. 无 default 分支
select 语句会在 case 分支中选择一个可读写成功的通道。
正确例子:
// concurrency/select/main.go
package main
import "fmt"
func main() {
ch1 := make(chan int, 1)
ch2 := make(chan int, 1)
ch1 <- 1
select {
case v, ok := <-ch1:
if ok {
fmt.Println("ch1通道", v)
}
case v, ok := <-ch2:
if ok {
fmt.Println("ch2通道", v)
}
}
}
// 输出
ch1通道 1
ch1通道有数据,因此进入了第一个case分支。- 这里展示了读通道,也可以给通道写数据,例:
case ch2<-2。 - 如果删除
ch1 <- 1,select语句会在 main 函数中一直等待,因此会造成死锁。
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [select]:
main.main()
C:/workspace/go/src/gobasic/cocurrency/select/main.go:9 +0xe7
2. 有 default 分支
为了防止 select 语句出现死锁,可以增加 default 分支。意思就是,当没有一个 case 分支可以进行通道读写,那就走 default 分支。
// ...
func main() {
ch1 := make(chan int, 1)
ch2 := make(chan int, 1)
select {
case v, ok := <-ch1:
if ok {
fmt.Println("ch1通道", v)
}
case v, ok := <-ch2:
if ok {
fmt.Println("ch2通道", v)
}
default:
fmt.Println("没有可读写通道")
}
}
// 输出
没有可读写通道
总结
这节课很关键,也是很容易出现问题的地方,我再针对重点的重点强调一下:
- 在函数调用前增加
go关键字,表示创建 Goroutine。 - 执行 Goroutine 不会同步等待,常用的使用
WaitGroup类型处理。 - Goroutine 的通信使用通道传输。
- 无缓冲的通道,不要进行同步读写,不然会阻塞。
最后,再揣摩一句话,不要用共享内存来通信,要用通信来共享内存。